
We present the first approach to build hierarchical task-driven 3D scene graphs of arbitrary indoor or outdoor environments using an uncalibrated monocular camera in real-time. We leverage geometric foundation models to estimate geometric attributes of the scene graph (e.g., object bounding boxes), but we also observe that traversability information (the "places" layer of a scene graph) can be directly reconstructed by adding an extra head to existing geometric foundation models, like VGGT.
Our approach is task-driven in the sense that we adjust the granularity of the objects and regions in the map depending on the task; for instance, during a manipulation task, our approach is able to resolve small knobs on a stove, while during a navigation task it can focus on large objects (e.g., the entire stove). However, in a major departure from related work, we consider the realistic case where the list of tasks is not predefined and fixed, but evolves as the robot operates. This naturally allows dealing with complex loco-manipulation tasks, where the robot can dynamically adjust its representation as the task unfolds. We dub the resulting approach FOUND-IT. FOUND-IT also includes an agentic approach to query information in the scene graph.
In addition to achieving 79% higher accuracy on the ASHiTA SG3D task grounding benchmark, we demonstrate FOUND-IT runs in real-time on a ground robot using a Jetson Thor. Furthermore, to highlight the robustness of our method, we demonstrate constructing 3D scene graphs on casually captured realtor apartment tours from YouTube. Code will be made available upon publication.
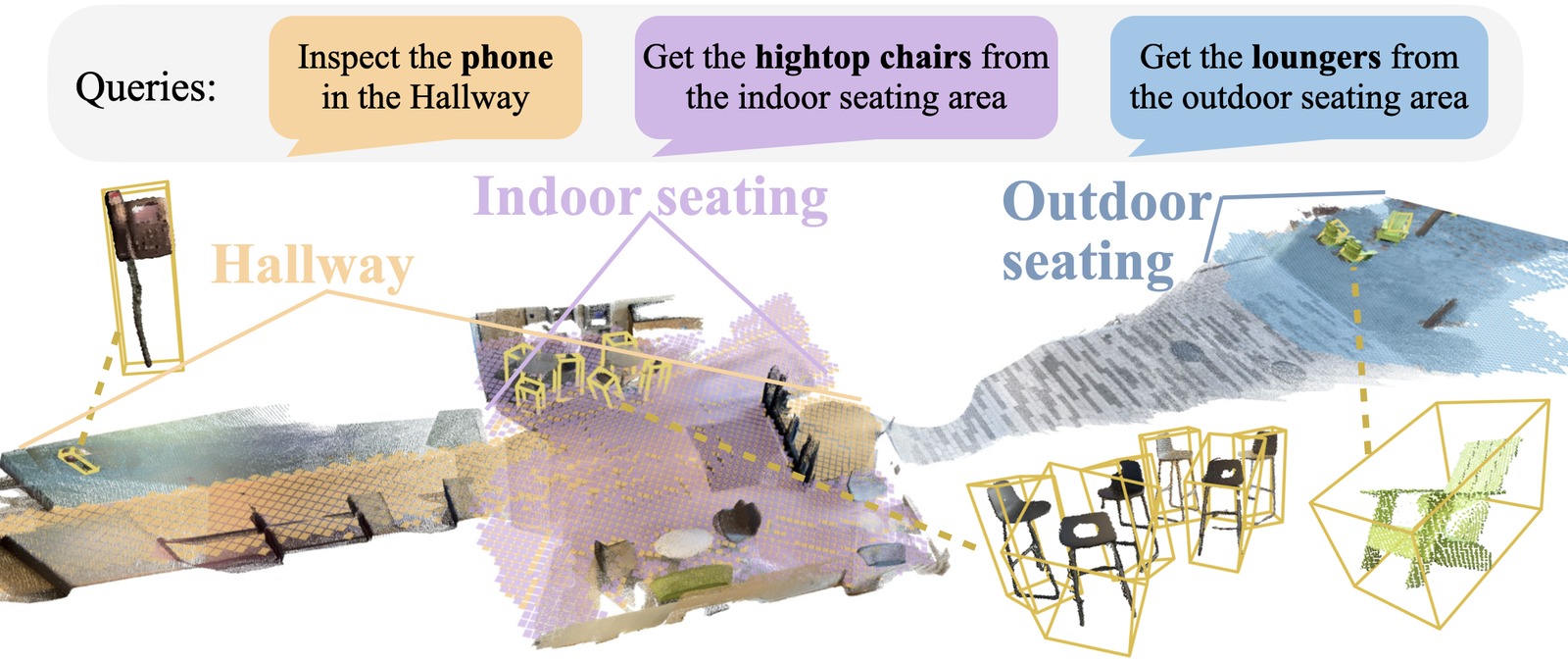
FOUND-IT is a real-time, open-set, hierarchical 3D scene graph construction system that generates maps in indoor and outdoor environments and dynamically adjusts their granularity depending on the task. Two ideas set it apart:
As shown above, an LLM agent grounds a sequence of tasks into a scene graph spanning indoor and outdoor areas.

Querying the same scene at two different granularities ("heart" and "washer"), and detecting many objects (45 washers). Granularity is determined at query time rather than fixed at mapping time. Left: 3D bounding boxes for both queries. Middle and right: the corresponding SAM 3 segmented keyframe for each query.

Finding multiple object instances for a single query, here five keyboards for the query "keyboard". Because FOUND-IT keeps passing matching keyframes to SAM 3 as long as new instances are found, it recovers all instances, unlike methods that segment only the top-scoring keyframe.
FOUND-IT achieves top performance on open-set 3D object detection on the Clio dataset and 79% higher accuracy on the ASHiTA SG3D task grounding benchmark. The full pipeline runs in real-time: 6 fps with VGGT and 7 fps with the lighter-weight Depth Anything 3 GFM on a 3090 GPU, with the GFM being the slowest component. By swapping in the lighter GFM, the full scene graph is constructed in real-time at 4 Hz onboard a Spot quadruped robot using a Jetson Thor. Querying a single object from visual memory takes about 100 ms, and clustering and extracting a region takes about 530 ms.
If you find this useful for your research, please consider citing our paper:
@article{Maggio26arxiv-FOUNDIT,
title={{FOUND-IT}: Foundation-model-first Task-driven {3D} Scene Graphs with Granularity on Demand},
author={Maggio, Dominic and Gorlo, Nicolas and Carlone, Luca},
journal={arXiv preprint arXiv:2605.25371},
year={2026}
}